RETE算法初窥
在规则世界里,RETE算法应该是无人不晓了,许多有名的规则引擎或者专家系统都是基于RETE算法实现的,包括Jess,JRules,Drools,CLIPS等。
算法简介
引用下wiki上关于RETE算法的定义:
RETE(/'ri:ti:/ or /'reiti:/)算法是个高效的可用于实现规则产生式系统(一种计算机程式,一般用于提供某种形式的人工智能,主要由基于行为的一系列规则构成)的模式匹配算法。
简而言之就是一套规则匹配优化算法。这个算法最早出现在1974年Dr Charles L. Forgy的一篇工作报告中,随后在1979年他的博士论文中完善,然后是1982年在《人工智能》杂志上的一篇文章。
原理简介
现实中,如果要实现一个由若干规则组成的系统?最原始的做法大致应该是(类似krrules,囧):匹配第一条规则,再匹配下一条规则,直到所有规则匹配完毕。这样的规则匹配时间就应该是与规则数量呈线性关系:即随着规则数目的增多,规则的匹配时间线性增长。而在一些由大量规则构成的专家系统(Expert System)中,这样的规则匹配效率达不到要求,这促使了RETE的诞生。
名词解释
有几个名词在描述RETE时会用到,他们大致是这些:
- facts:指RETE网络中的输入项,数据元祖(data tuples)。
- rule:指用于对facts进行模式匹配的条件设置。
- action:指满足规则匹配后的动作处理。
- production:由一个或多个规则加上一系列动作构成。
- WME:当facts被插入引擎,即为它们创立(working memory elements)。
匹配流程
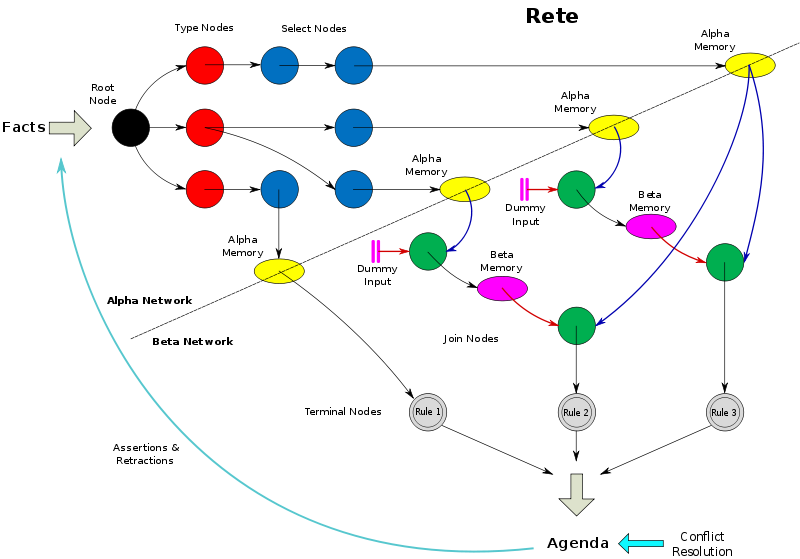
参考上图,一个完整的RETE规则匹配流程大致是这样的:
- 一个或多个事实facts被assert进RETE规则网络,
- 网络根据配置的规则rules进行模式匹配,并为facts创建WMEs,
- 对于触发规则的facts创建activitions并放入agenda中,
- agenda根据触发规则优先级salience确立触发次序,
- 最后执行action。
节点分类
最初Dr Charles L. Forgy提出的RETE网络是由四种节点构成,分别为:
- root node(输入起始节点)
- one-input node(单fact的条件匹配)
- two-input node(多facts的联合join)
- terminal node(走到此节点,则规则匹配)
人们在算法实现时又常常将one-input node再细分为:
- Type Node:定位事实属性,确定fact的class,在krrules实现时将此步称为确定所属数据源,这为后续的节点定义和操作做好了铺垫;
- Alpha Node:对fact的属性进行匹配判断,比如对一个person的fact,判断其age是否大于18,gender是否为male等;
- Beta Node:则相对更为复杂一些,需要实现了两个fact的关联与匹配(比如一个person是否出现在一次party人员名单中)。 具体的节点和功能作用,此处不再赘述了,想要更详细的了解rete算法的同学,除了阅读上面的原作者论文,还可参考这篇文章:《Production Matching For Large Learning Systems》,有好几十页的篇幅详细的介绍了RETE算法。
算法总结
以上,可以发现RETE的优点在于:
- 通过节点共享(node sharing)减少了规则中重复模式(pattern)的计算;
- 存储了部分匹配fact联合join匹配的结果,这样当facts少量变化时,免去未变化的计算量。
了解优点后,我们也很容易总结发现RETE相对于传统的线性匹配的优势点或优化场景在于:
大量规则(规则间具有某些重复pattern的情况),少量变化(规则判定的facts不是每次都重新assert)
在这样的场景下RETE规则匹配算法会得到更好的效果,这对规则的设计与开发者是有些指导意义的。
应用案例
RETE在诞生以后,被广泛的用于专家系统和规则引擎的构建中,其中著名的有:
- 专家系统CLIPS:源于1984年NASA的人工智能项目,现已开源,由C编写,简单看过源码,逻辑组织还是比较清晰的,后面详细阅读过源码后,有机会再专门介绍下。
- 规则引擎Drools:现在是jboss的开源项目,现已被广泛应用到各商业产品的开发中,drools文档中有关于RETE的实现RETEOO通俗易懂的介绍,可参考:http://docs.jboss.org/drools/release/6.0.0.Beta5/drools-expert-docs/html/ch01.html#d0e515